The Ordering Service¶
涉众:架构师、排序服务管理员、通道创建者
这个话题是一个概念性的介绍顺序的概念,排序器与peer相互作用,如何在一个交易流程中所发挥的作用,和当前可用的排序服务的实现概述,尤其关注 Raft 排序服务实现。
What is ordering?¶
许多分布式区块链,如以太坊(Ethereum)和比特币(Bitcoin),都不是许可链的,这意味着任何节点都可以参与共识过程,在共识过程中,交易被排序并捆绑成区块。因为这个事实,这些系统依靠概率共识算法最终保证账本一致性高的概率,但仍容易受到不同的账本(有时也称为一个账本“分叉”),在网络中不同的参与者对于交易顺序有不同的观点。
超级账本Fabric的工作方式不同。它具有一种称为排序器的节点(也称为“排序节点”),它执行交易排序,并与其他节点一起形成一个排序服务。因为Fabric的设计依赖于确定性的共识算法,所以由排序服务生成的任何区块由peer验证都能保证是最终的和正确的。账本不能像在其他分布式区块链中那样分叉。
除了促进确定性之外,将链码执行的背书(发生在peer)与排序分离,还在性能和可伸缩性方面提供了Fabric的优势,消除了由相同节点执行和排序时可能出现的瓶颈。
Orderer nodes and channel configuration¶
除了排序角色之外,排序器还维护允许创建通道的组织列表。此组织列表称为“联盟”,列表本身保存在“排序器系统通道”(也称为“排序系统通道”)的配置中。默认情况下,此列表及其所在的通道只能由排序器管理员编辑。请注意,排序服务可以保存这些列表中的几个,这使得联盟成为Fabric多租户的载体。
排序器还对通道执行基本访问控制,限制谁可以读写数据,以及谁可以配置数据。请记住,谁有权修改通道中的配置元素取决于相关管理员在创建联盟或通道时设置的策略。配置交易由排序器处理,因为它需要知道当前策略集合来执行其基本形式的访问控制。在这种情况下,排序器处理配置更新,以确保请求者拥有正确的管理权限。如果是,排序器将根据现有配置验证更新请求,生成一个新的配置交易,并将其打包到一个区块中,该区块将转发给通道上的所有peer。然后peer处理配置交易,以验证排序器批准的修改确实满足通道中定义的策略。
Orderer nodes and Identity¶
与区块链网络交互的所有东西,包括peer、应用程序、管理员和排序器,都从它们的数字证书和成员服务提供者(MSP)定义中获取它们的组织身份。
有关身份和MSP的更多信息,请查看我们关于身份和成员的文档。
与peer一样,排序节点属于组织。与peer类似,应该为每个组织使用单独的证书颁发机构(CA)。这个CA是否将作为根CA发挥作用,或者您是否选择部署根CA,然后部署与该根CA关联的中间CA,这取决于您。
Orderers and the transaction flow¶
Phase one: Proposal¶
从我们对peer节点的讨论中,我们已经看到它们构成了区块链网络的基础,托管账本,应用程序可以通过智能合约查询和更新这些账本。
具体地说,希望更新账本的应用程序涉及到一个分三个阶段的过程,该过程确保区块链网络中的所有peer保持它们的账本彼此一致。
在第一阶段,客户端应用程序将交易提案发送给一组peer,这些peer将调用一个智能合约来生成一个提议的账本更新,然后背书结果。背书peer此时不将提案的更新应用于其账本副本。相反,背书的peer将向客户机应用程序返回一个提案响应。已背书的交易提案最终将在第二阶段被排序为区块,然后在第三阶段分发给所有peer进行最终验证和提交。
要深入了解第一个阶段,请参阅peer主题。
Phase two: Ordering and packaging transactions into blocks¶
在完成交易的第一阶段之后,客户端应用程序已经从一组peer接收到一个经过背书的交易提案响应。现在是交易的第二阶段。
在此阶段,应用程序客户端将包含已背书交易提案响应的交易提交到排序服务节点。排序服务创建交易区块,这些交易区块最终将分发给通道上的所有peer,以便在第三阶段进行最终验证和提交。
排序服务节点同时接收来自许多不同应用程序客户端的交易。这些排序服务节点一起工作,共同组成排序服务。它的工作是将提交的交易按定义良好的顺序安排成批次,并将它们打包成区块。这些区块将成为区块链的区块!
区块中的交易数量取决于区块的期望大小和最大运行时间相关的通道配置参数(确切地说,是BatchSize和BatchTimeout参数)。然后将这些区块保存到排序器的账本中,并分发给已经加入通道的所有peer。如果此时恰好有一个peer关闭,或者稍后加入通道,则在重新连接到排序服务节点或与另一个peer通信(闲聊)之后,通道将接收到这些区块。我们将在第三阶段看到peer如何处理这个区块。
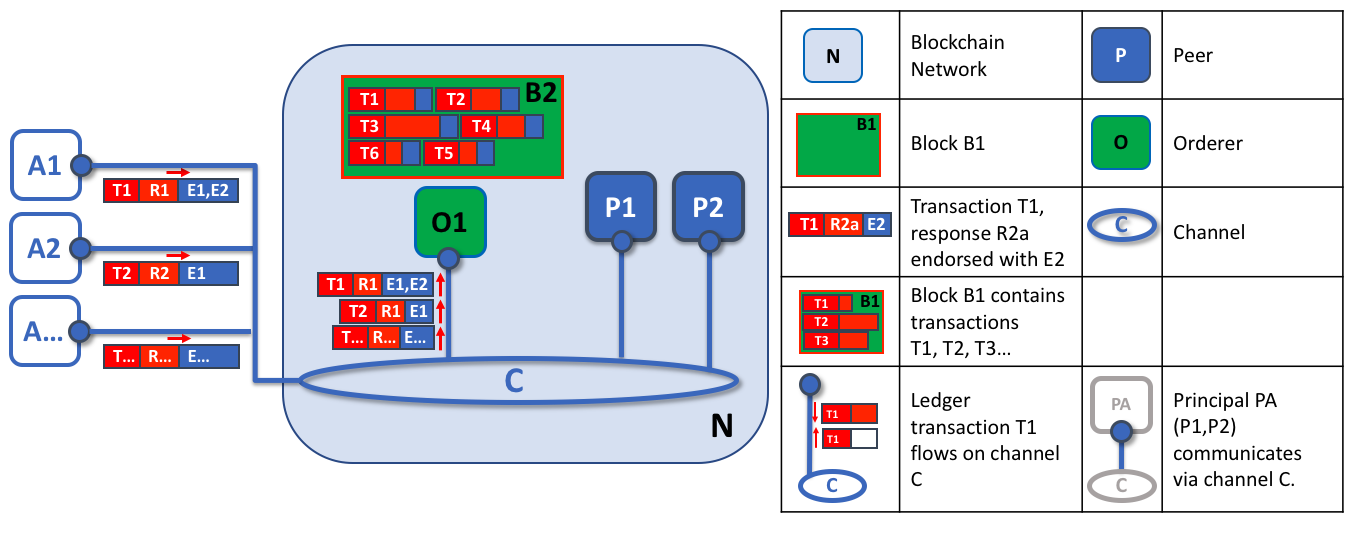 Orderer1
Orderer1
排序节点的第一个角色是打包提案的账本更新。在本例中,应用程序A1向排序器O1发送由E1和E2背书的交易T1。同时,应用程序A2将E1背书的交易T2发送给排序器O1。O1将来自应用程序A1的交易T1和来自应用程序A2的交易T2以及来自网络中其他应用程序的交易打包到区块B2中。我们可以看到,在B2中,交易顺序是T1、T2、T3、T4、T6、T5——这可能不是这些交易到达排序器的顺序!(这个例子显示了一个非常简单的排序服务配置,只有一个排序节点。)
值得注意的是,一个区块中交易的顺序不一定与排序服务接收的顺序相同,因为可能有多个排序服务节点几乎同时接收交易。重要的是,排序服务将交易放入严格的顺序中,并且peer在验证和提交交易时将使用这个顺序。
区块内交易的严格排序使得超级账本Fabric与其他区块链稍有不同,在其他区块链中,相同的交易可以被打包成多个不同的区块,从而形成一个链。在超级账本Fabric中,由排序服务生成的区块是最终的。一旦一笔交易被写进一个区块,它在账本中的地位就得到了不可动摇的保证。正如我们前面所说,超级账本Fabric的终结性意味着没有账本分支——经过验证的交易永远不会被还原或删除。
我们还可以看到,虽然peer执行智能合约并处理交易,但是排序器绝对不会这样做。到达排序器的每个授权交易都被机械地打包在一个区块中——排序器不判断交易的内容(前面提到的通道配置交易除外)。
在第二阶段的末尾,我们看到排序器负责收集提议的交易更新、排序它们并将它们打包成区块,以便分发,这些简单但重要的过程。
Phase three: Validation and commit¶
交易工作流的第三个阶段涉及到从排序器到peer的区块的分发和随后的验证,这些区块可以应用到账本中。
阶段3从排序器将区块分发给连接到它的所有peer开始。同样值得注意的是,并不是每个peer都需要连接到一个排序器——peer可以使用gossip协议将区块级联到其他peer。
每个peer将独立地验证分布式区块,但以确定的方式验证,确保账本保持一致。具体来说,每个peer的通道将区块中的每个交易进行验证,以确保得到需要的组织peer的背书,其背书吻合,它还没有被其他最近已提交交易搞失效。无效的交易仍然保留在排序器创建的不可变区块中,但是peer将它们标记为无效,并且不更新账本的状态。
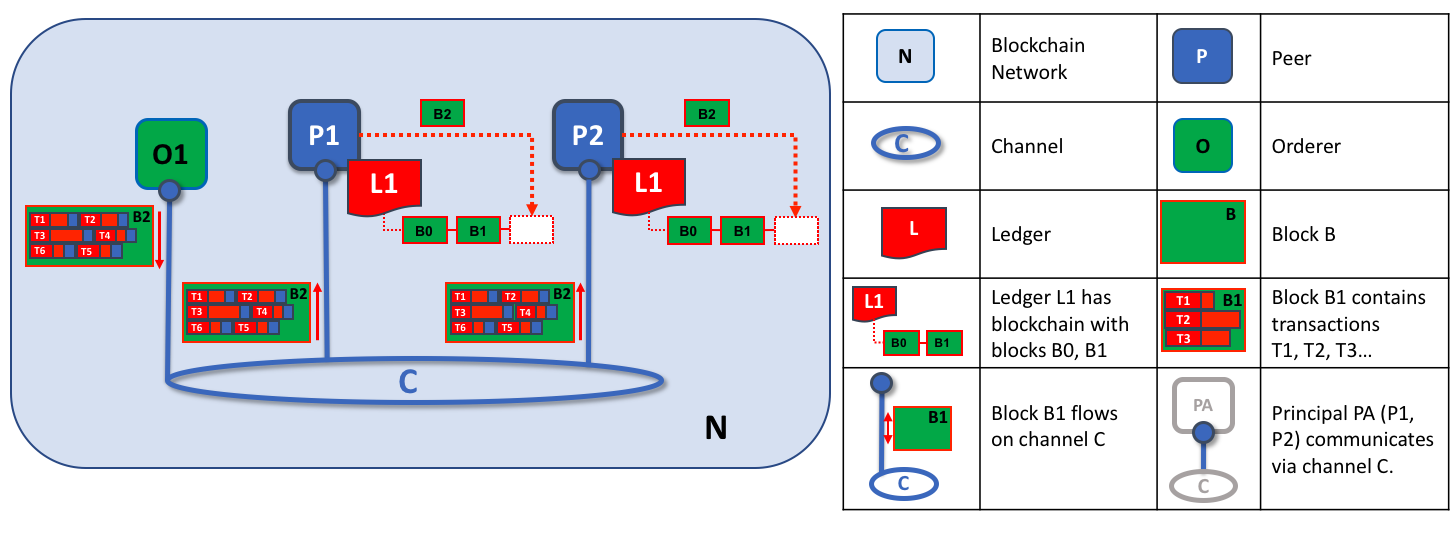 Orderer2
Orderer2
排序节点的第二个角色是将区块分发给peer节点。在本例中,排序器O1将区块B2分配给peer P1和peer P2。peer P1处理区块B2,导致在P1上的账本L1中添加一个新区块。同时,peer P2处理区块B2,从而将一个新区块添加到P2上的账本L1中。一旦这个过程完成,peer P1和P2上的账本L1就会一直更新,并且每个账本L1都可以通知连接的应用程序交易已经被处理。
总之,第三阶段看到的是由排序服务生成的区块一致地应用于账本。将交易严格地按区块排序,允许每个peer验证交易更新是否在整个区块链网络上一致地应用。
要更深入地了解阶段3,请参阅peer主题。
Ordering service implementations¶
虽然当前可用的每个排序服务都以相同的方式处理交易和配置更新,但是仍然有几种不同的实现可以在排序服务节点之间就严格的交易排序达成共识。
有关如何建立排序节点(无论该节点将在什么实现中使用)的信息,请参阅关于建立排序节点的文档。
Solo
The Solo implementation of the ordering service is aptly named: it features only a single ordering node. As a result, it is not, and never will be, fault tolerant. For that reason, Solo implementations cannot be considered for production, but they are a good choice for testing applications and smart contracts, or for creating proofs of concept. However, if you ever want to extend this PoC network into production, you might want to start with a single node Raft cluster, as it may be reconfigured to add additional nodes.
Raft
New as of v1.4.1, Raft is a crash fault tolerant (CFT) ordering service based on an implementation of Raft protocol in
etcd. Raft follows a “leader and follower” model, where a leader node is elected (per channel) and its decisions are replicated by the followers. Raft ordering services should be easier to set up and manage than Kafka-based ordering services, and their design allows different organizations to contribute nodes to a distributed ordering service.Kafka
Similar to Raft-based ordering, Apache Kafka is a CFT implementation that uses a “leader and follower” node configuration. Kafka utilizes a ZooKeeper ensemble for management purposes. The Kafka based ordering service has been available since Fabric v1.0, but many users may find the additional administrative overhead of managing a Kafka cluster intimidating or undesirable.
Solo¶
如上所述,在开发测试、开发或概念验证网络时,单独排序服务是一个不错的选择。出于这个原因,它是默认的排序服务部署在我们构建第一个网络教程),从其他网络组件的角度来看,一个Solo排序服务处理交易相同于更复杂的Kafka和Raft实现,而节省维护和升级多个节点和集群的管理开销。由于Solo排序服务不能容错,因此它永远不应该被认为是生产区块链网络的可行替代方案。对于只希望从单个排序节点开始但将来可能希望增长的网络,单节点Raft集群是更好的选择。
Raft¶
有关如何配置Raft排序服务的信息,请参阅有关配置Raft排序服务的文档。
生产网络的排序服务选择,建立Raft协议的Fabric实现使用一个“领导者和跟随者”模式,一个领导者的动态排序节点中选出一个通道(这个集合的节点称为“同意者”),和领导者将信息复制到跟随者节点。因为系统可以承受节点的损失,包括领导者节点,只要还有大量的有序节点(称为“quorum”)剩余,Raft被称为“崩溃容错”(crash fault tolerant, CFT)。换句话说,如果一个通道中有三个节点,它可以承受一个节点的丢失(剩下两个)。如果一个通道中有五个节点,则可能会丢失两个节点(留下三个剩余节点)。
从它们提供给网络或通道的服务的角度来看,Raft和现有的基于kafka的排序服务我们将在稍后讨论)是相似的。它们都是使用领导者和跟随者设计的CFT排序服务。如果您是应用程序开发人员、智能合约开发人员或peer管理员,您不会注意到基于Raft和Kafka的排序服务之间的功能差异。然而,有几个主要的差异值得考虑,特别是如果你打算管理一个排序服务:
Raft is easier to set up. Although Kafka has scores of admirers, even those admirers will (usually) admit that deploying a Kafka cluster and its ZooKeeper ensemble can be tricky, requiring a high level of expertise in Kafka infrastructure and settings. Additionally, there are many more components to manage with Kafka than with Raft, which means that there are more places where things can go wrong. And Kafka has its own versions, which must be coordinated with your orderers. With Raft, everything is embedded into your ordering node.
Kafka and Zookeeper are not designed to be run across large networks. They are designed to be CFT but should be run in a tight group of hosts. This means that practically speaking you need to have one organization run the Kafka cluster. Given that, having ordering nodes run by different organizations when using Kafka (which Fabric supports) doesn’t give you much in terms of decentralization because the nodes will all go to the same Kafka cluster which is under the control of a single organization. With Raft, each organization can have its own ordering nodes, participating in the ordering service, which leads to a more decentralized system.
Raft is supported natively. While Kafka-based ordering services are currently compatible with Fabric, users are required to get the requisite images and learn how to use Kafka and ZooKeeper on their own. Likewise, support for Kafka-related issues is handled through Apache, the open-source developer of Kafka, not Hyperledger Fabric. The Fabric Raft implementation, on the other hand, has been developed and will be supported within the Fabric developer community and its support apparatus.
Where Kafka uses a pool of servers (called “Kafka brokers”) and the admin of the orderer organization specifies how many nodes they want to use on a particular channel, Raft allows the users to specify which ordering nodes will be deployed to which channel. In this way, peer organizations can make sure that, if they also own an orderer, this node will be made a part of a ordering service of that channel, rather than trusting and depending on a central admin to manage the Kafka nodes.
Raft is the first step toward Fabric’s development of a byzantine fault tolerant (BFT) ordering service. As we’ll see, some decisions in the development of Raft were driven by this. If you are interested in BFT, learning how to use Raft should ease the transition.
注:与Solo和Kafka类似,Raft排序服务在向客户发送收据确认后可能会丢失交易。例如,如果领导者崩溃的时间与跟随者崩溃的时间大致相同时提供接收确认。因此,无论如何,应用程序客户端都应该侦听peer的交易提交事件(检查交易有效性),但是应该格外小心,以确保客户端还能优雅地容忍一个超时,在这个超时中,交易没有在配置的时间范围内提交。根据应用程序的不同,可能需要在这样的超时之后重新提交交易或收集一组新的背书。
Raft concepts¶
尽管Raft提供了许多与Kafka相同的功能(尽管是在一个更简单、更容易使用的包中),但它在幕后的功能与Kafka有本质上的不同,并向Fabric引入了许多新概念,或对现有概念进行了扭曲。
日志条目。Raft排序服务中的主要工作单元是一个“日志条目”,其中包含称为“日志”的完整序列。如果大多数成员(换句话说是一个法定人数)同意条目及其顺序,从而复制不同排序器上的日志,那么我们认为日志是一致的。
批准者集合。排序节点积极参与给定通道的共识机制,并接收该通道的复制日志。这可以是所有可用的节点(在单个集群中或者在多个集群中),也可以是这些节点的子集。
有限状态机(FSM)。Raft中的每个排序节点都有一个FSM,它们共同用于确保各个排序节点中的日志序列是确定的(以相同的顺序编写)。
法定人数。描述需要确认提案以便能够对交易排序的最小同意人数。对于每个批准者集合,这是大多数节点。在具有五个节点的集群中,必须有三个节点可用,才能有一个法定人数。如果节点的法定人数因任何原因不可用,则排序服务集群对于通道上的读和写操作都不可用,并且不能提交任何新日志。
领导者。这并不是一个新概念——正如我们所说,Kafka也使用了领导者——但是在任何给定的时间,通道的批准者集合都选择一个节点作为领导者,这一点非常重要(我们稍后将在Raft中描述这是如何发生的)。领导者负责接收新的日志条目,将它们复制到跟随者的排序节点,并在认为提交了某个条目时进行管理。这不是一种特殊类型的排序器。它只是排序器在某些时候可能扮演的角色,而不是由环境决定的其他角色。
跟随者。再次强调,这不是一个新概念,但是理解跟随者的关键是跟随者从领导者那里接收日志并确定地复制它们,确保日志保持一致。我们将在关于领导者选举的部分中看到,跟随者也会收到来自领导者的“心跳”消息。如果领导者在一段可配置的时间内停止发送这些消息,跟随者将发起一次领导者选举,其中一人将当选为新的领导者。
Raft in a transaction flow¶
每个通道都在Raft协议的单独实例上运行,该协议允许每个实例选择不同的领导者。这种配置还允许在集群由不同组织控制的有序节点组成的用例中进一步分散服务。虽然所有Raft节点都必须是系统通道的一部分,但它们不一定必须是所有应用程序通道的一部分。通道创建者(和通道管理员)能够选择可用排序器的子集,并根据需要添加或删除排序节点(只要一次只添加或删除一个节点)。
虽然这种配置以冗余心跳消息和线程的形式产生了更多的开销,但它为BFT奠定了必要的基础。
在Raft中,交易(以提案或配置更新的形式)由接收交易的排序节点自动路由到该通道的当前领导者。这意味着peer和应用程序在任何特定时间都不需要知道谁是领导者节点。只有排序节点需要知道。
当排序器验证检查完成后,将按照我们交易流程的第二阶段的描述,对交易进行排序、打包成区块、协商并分发。
Architectural notes¶
How leader election works in Raft¶
尽管选举领导者的过程发生在排序器的内部过程中,但是值得注意的是这个过程是如何工作的。
Raft节点总是处于以下三种状态之一:跟随者、候选人或领导者。所有节点最初都是作为跟随者开始的。在这种状态下,他们可以接受来自领导者的日志条目(如果其中一个已经当选),或者为领导者投票。如果在一段时间内没有接收到日志条目或心跳(例如,5秒),节点将自我提升到候选状态。在候选状态中,节点从其他节点请求选票。如果候选人获得法定人数的选票,那么他就被提升为领导者。领导者必须接受新的日志条目并将其复制到跟随者。
要了解领导者选举过程的可视化表示,请查看数据的秘密生活。
Snapshots¶
如果一个排序节点宕机,它如何在重新启动时获得它丢失的日志?
虽然可以无限期地保留所有日志,但是为了节省磁盘空间,Raft使用了一个称为“快照”的过程,在这个过程中,用户可以定义日志中要保留多少字节的数据。这个数据量将符合一定数量的区块(这取决于区块中的数据量)。注意,快照中只存储完整的区块)。
例如,假设滞后副本R1刚刚重新连接到网络。它最新的区块是100。领导者L位于第196块,并被配置为在本例中快照20区块数据量。R1因此将从L接收区块180,然后为区块101到180发送请求。区块180到196然后将通过正常Raft协议复制到R1。
Kafka¶
Fabric支持的另一个容错崩溃排序服务是对Kafka分布式流平台的改编,将其用作排序节点集群。您可以在Apache Kafka网站上阅读更多关于Kafka的信息,但是在更高的层次上,Kafka使用与Raft相同的概念上的“领导者和跟随者”配置,其中交易(Kafka称之为“消息”)从领导者节点复制到跟随者节点。在领导者节点宕机的情况下,一个跟随者成为领导者, 排序可以继续,确保容错,就像Raft一样。
Kafka集群的管理,包括任务协调、集群成员、访问控制和控制器选择等,由ZooKeeper集合及其相关api来处理。
Kafka集群和ZooKeeper 集合的设置是出了名的棘手,所以我们的文档假设您对Kafka和ZooKeeper 有一定的了解。如果您决定在不具备此专业知识的情况下使用Kafka,那么在试验基于Kafka的排序服务之前,至少应该完成Kafka快速入门指南的前六个步骤。您还可以参考这个示例配置文件来简要解释Kafka和ZooKeeper的合理默认值。
要了解如何启动基于Kafka的排序服务,请查看我们关于Kafka的文档。