架构起源¶
注解
本文档表现了Hyperledger Fabric v1.0的初始架构提案。虽然Hyperledger Fabric实现在概念上遵循了本架构提案,但是在实现过程中一些细节已经被更改。最初的架构方案是按照最初准备的方式呈现的。要更精确地表示架构,请参见`Hyperledger Fabric:一个许可区块链的分布式操作系统<https://arxiv.org/abs/1801.10228v2>`__。
超级账本Fabric架构具有以下优点:
链码**链码信任的灵活性**该架构将链码(区块链应用程序)的*信任假设*与排序的信任假设分开。换句话说,排序服务可能由一组节点(排序器)提供,并允许其中一些节点失败或行为不端,而且每个链码的背书者可能不同。
可伸缩性 由于负责特定链码的背书节点与排序器正交,因此系统的伸缩性可能比由相同节点执行这些功能要好。特别是,当不同的链码指定了互斥的背书器时,这将导致在背书器之间对链码进行分区,并允许并行的链码执行(背书)。此外,链码执行从排序服务的关键路径中删除,链码执行的成本可能很高。
**第一部分:与Hyperledger Fabric v1**相关的架构元素
系统架构
交易背书的基本流程
背书策略
第二部分:架构的Post-v1 元素
账本检查点(修剪)
1. 系统架构¶
区块链是一个分布式系统,由许多相互通信的节点组成。区块链运行名为链码的程序,保存状态和账本数据,并执行交易。链码是中心元素,因为交易是在链码上调用的操作。交易必须“背书”,只有背书的交易才可以提交并对状态产生影响。可能存在一个或多个用于管理函数和参数的特殊链码,统称为*系统链码*。
1.1. 交易¶
交易可分为两类:
*部署交易*创建新的链码并将程序作为参数。当部署交易成功执行时,链码会被安装在区块链上。
*调用交易*在以前部署的链码上下文中执行操作。调用交易引用链码和它提供的某个函数。当成功时,链码执行指定的函数,这可能涉及修改相应的状态,并返回输出。
如后面所述,部署交易是调用交易的特殊情况,其中创建新链码的部署交易对应于系统链码上的调用交易。
备注: 本文档目前假设交易要么创建新的链码,要么调用*一个*已部署链码提供的操作。这个文档还没有描述: a)查询(只读)交易的优化(包含在v1中),b)对跨链码交易的支持(v1后续的特性).
1.2. 区块链数据结构¶
1.2.1 状态¶
区块链的最新状态(或者简单地说,状态)被建模为一个版本化的键值存储(KVS),其中键是名称,值是任意的blob。这些条目由区块链上运行的链码(应用程序)通过“put”和“get”KVS-操作操作。状态被持久地存储,并记录对状态的更新。注意,版本化的KVS被用作状态模型,实现可以使用既有的KVS,也可以使用RDBMS或任何其他解决方案。
更正式地说,状态``s`` 被建模为映射``K -> (V X N)``的一个元素,其中:
``K``是一组键
V是一组值N``是版本号的无穷有序集合。单射函数 ``next: N -> N接受``N``的元素并返回下一个版本号。
V``和``N 都包含一个特殊的元素|falsum|(空类型),即``N`` 是最低的元素。最初,所有键都映射到(⊥, ⊥)。对于``s(k)=(v,ver)``,我们用``s(k).value``表示``v``, 用``s(k).version``表示``ver`` 。
KVS操作模型如下:
put(k,v)fork∈Kandv∈V, 将区块链状态设置为s,然后将状态修改为s',于是s'(k)=(v,next(s(k).version))withs'(k')=s(k')for allk'!=k.get(k)返回``s(k)``。
状态由节点维护,而不是由排序器和客户端维护。
**状态分区。**KVS中的键可以从它们的名称中识别出属于某个特定链码,因为只有某个链码的交易可以修改属于这个链码的键。原则上,任何链码都可以读取属于其他链码的键。支持跨链码交易,可以修改属于两个或多个链码的状态,这是一个v1后续版本的特性。
1.2.2 账本¶
账本提供了一个可验证的历史记录,记录了在系统运行期间发生的所有成功的状态更改(我们说的*有效的*交易)和失败的状态更改尝试(我们说的*无效的*交易)。
账本是由排序服务(参见第1.3.3节)构造的,它是(有效或无效的)交易的*区块*的完全有序哈希链。哈希链强制账本中的区块的总顺序,每个区块包含一个完全有序的交易数组。这强制为所有交易指定了顺序。
账本保存在所有的节点上,也可以选择保存在部分排序器上。在排序器的上下文中,我们将账本称为“排序器账本”,而在节点的上下文中,我们将账本称为“节点账本”。节点账本 与``排序器账本`` 的不同之处在于,节点在本地维护一个比特掩码,该比特掩码将有效的交易与无效的交易区分开来(有关详细信息,请参阅XX节)。
如第XX节(v1后续特性)所述的,节点可以修剪 节点账本 。排序器维护“排序器账本”以获得容错性和(“节点账本”的)可用性,并可以决定随时对其进行修剪,前提是排序服务的属性得到了维护(参见第1.3.3节)。
账本允许节点重放所有交易的历史并重建状态。因此,Sec 1.2.1中描述的状态是一个可选的数据结构。
1.3. node节点¶
node节点是区块链的通信实体。一个“node节点”只是一个逻辑功能,因为不同类型的多个node节点可以运行在同一个物理服务器上。重要的是node节点如何在“信任域”中分组并与控制它们的逻辑实体相关联。
有三种类型的node节点:
客户端**或**提交客户端:是一个向背书方提交实际交易调用并向排序服务广播交易提议的客户端。
peer节点:是一个提交交易并维护状态和账本副本的node节点(参见第1.2节)。此外,peer节点可以扮演一个特殊的**背书人**角色。
排序服务node节点**或**排序器:是一个运行实现交付担保的通信服务的node节点,例如原子性或总顺序广播。
接下来将更详细地解释node节点的类型。
1.3.1. 客户端¶
客户端扮演了代表最终用户的实体。它必须连接到与区块链通信的peer节点。客户端可以连接到它所选择的任何peer节点。客户端创建并调用交易。
如第2节所详细介绍的,客户端同时与peer节点和排序服务通信。
1.3.2. peer节点¶
peer节点接收来自排序服务的“区块”形式的有序状态更新,并维护状态和账本。
链码peer节点还可以承担**背书节点**或**背书人**的特殊角色。一个*背书节点*的特殊函数根据一个特定链码重现,包括在交易提交之前*背书*一个交易。每个链码都可以指定一个*背书策略*,该策略可以引用一组背书节点。策略为有效的交易背书(通常是一组背书人的签名)定义了必要条件和充分条件,后面的第2和3节将对此进行描述。在安装新链码的部署交易的特殊情况下,(部署)背书策略指定为系统链码的背书策略。
1.3.3. 排序服务node节点(排序器)¶
排序器*组成*排序服务,即,提供交付担保的通信结构。排序服务可以以不同的方式实现:从集中式服务(例如,在开发和测试中使用)到针对不同网络和node节点故障模型的分布式协议。
排序服务为客户端和peer节点提供共享的“通信通道”,为包含交易的消息提供广播服务。客户端连接到通道,并可以在通道上广播消息,然后将消息传递给所有peer节点。该通道支持所有消息的“原子”传递,即与全顺序传递和(特定于实现的)可靠性的消息通信。换句话说,通道将相同的消息输出给所有连接的peer节点,并将它们以相同的逻辑顺序输出给所有peer节点。这种原子通信保证在分布式系统上下文中也称为*全顺序广播*、原子广播*或*共识。所通信的消息是要包含在区块链状态中的候选交易。
**分区(排序服务通道)。**排序服务可能支持多个*通道*,类似于发布/订阅(发布/订阅)消息系统的*主题*。客户端可以连接到给定的通道,然后可以发送消息并获取到达的消息。通道可以看作是分区,连接到一个通道的客户端不知道其他通道的存在,但是客户端可以连接到多个通道。尽管在超级账本Fabric中包含的一些排序服务实现支持多个通道,但为了简化表示,在本文档的其余部分中,我们假设排序服务由一个通道/主题组成。
**排序服务API。**peer节点通过排序服务提供的接口连接到排序服务提供的通道。排序服务API由两个基本操作(一般称*异步事件*)组成:
TODO 添加API的一部分,用于在客户端/peer节点指定的序列号下获取特定的区块。
广播(blob) ``:客户端调用它来广播任意消息``blob``以便在通道上传播。在BFT上下文中,当向服务发送请求时,也称为``request(blob)。deliver(seqno, prevhash, blob):排序服务在peer节点调用这个函数,以传递消息``blob`` ,其中包含指定的非负整数序列号 (seqno)和最近交付的blob的散列(prevhash)。换句话说,它是来自排序服务的输出事件。deliver()``在发布订阅系统中有时也被称为`notify(),或在BFT系统中被称为``commit()``。
账本和区块构成。账本(参见第1.2.2节)包含排序服务输出的所有数据。简而言之,它是``deliver(seqno, prevhash, blob)``事件的序列,这些事件根据前面描述的``prevhash`` 的计算形成一个哈希链。
大多数时候,出于效率的考虑,排序服务不会输出单个交易(blob),而是在单个``deliver``事件中对blob和输出*区块*进行分组(批处理)。在这种情况下,排序服务必须强制并传递每个区块中blob的确定性排序。区块中的区块数可以由排序服务实现动态选择。
下面,为了便于表达,我们定义了排序服务属性(本小节的其余部分),并解释了交易背书的工作流(第2节),假设每个``deliver`` 事件有一个blob。这些很容易扩展到区块,假设一个区块的“交付”事件对应于一个区块中的每个blob的单独的 ``deliver``事件序列,根据上面提到的区块中blob的确定性顺序。
排序服务属性
排序服务(或原子广播通道)的保证规定了广播消息发生了什么,以及传递的消息之间存在什么关系。这些保证如下:
安全(一致性保证):只要peer节点连接到通道的时间足够长(它们可以断开连接或崩溃,但会重新启动和重新连接),它们将看到一个*相同的*已交付的``(seqno, prevhash, blob)`` 消息序列。这意味着输出(
deliver()``事件)在所有peer节点上以*相同的顺序*发生,并根据序列号,为相同的序列号携带*相同的内容* (``blob和``prevhash``)。注意,这只是一个“逻辑顺序”,一个peer节点上的``deliver(seqno, prevhash, blob)`` 不需要与另一个peer节点上输出相同的``deliver(seqno, prevhash, blob)`` 消息发生实时关联。换句话说,给定一个特定的’seqno, 没有*两个正确的peer节点提供了*不同的*``prevhash`` 或``blob`` ‘值。此外,除非某个客户端(peer节点)实际调用了``broadcast(blob)`` ,否则不会传递任何值``blob`` ,即每个广播的blob只传递*一次。此外,
deliver()``事件包含前一个``deliver()事件中的数据的加密哈希(prevhash)。当排序服务实现原子广播保证时,prevhash``是``deliver()``事件的参数和序号的加密哈希``seqno-1。这将在``deliver()``事件之间建立一个哈希链,用于帮助验证排序服务输出的完整性,后面的第4和第5节将对此进行讨论。在第一个``deliver()``事件的特殊情况下,``prevhash``有一个默认值。存活性(交付保证):排序服务的存活性保证由排序服务的实现决定。准确的保证可能取决于网络和node节点故障模型。
原则上,如果提交的客户端没有失败,那么排序服务应该确保连接到排序服务的每个正确peer节点最终交付每个提交的交易。
总而言之,排序服务确保以下特性:
*协议。*对于正确peer节点上的任何两个具有相同
seqno``的事件``deliver(seqno, prevhash0, blob0)和``deliver(seqno, prevhash1, blob1)`` ,prevhash0==prevhash1``和``blob0==blob1;哈希链完整性。 对于正确peer节点上的任何两个事件``deliver(seqno-1, prevhash0, blob0)`` 和
deliver(seqno, prevhash, blob),prevhash = HASH(seqno-1||prevhash0||blob0)。没有跳过。如果排序服务在一个正确的peer节点*p*上输出``deliver(seqno, prevhash, blob)`` ,例如
seqno>0,那么*p*已经交付了一个事件``deliver(seqno-1, prevhash0, blob0)``。没有创建。在正确的peer节点上的任何事件``deliver(seqno, prevhash, blob)``之前,在一些(可能不同的)peer节点上必然有一个``broadcast(blob)``事件;
没有复制duplication (optional, yet desirable)。对任何两个事件``broadcast(blob)`` 和``broadcast(blob’)``,当两个事件``deliver(seqno0, prevhash0, blob)`` 和
deliver(seqno1, prevhash1, blob')``发生在正确的peer节点并且 ``blob == blob',那么``seqno0==seqno1``和``prevhash0==prevhash1``。存活性。如果一个正确的客户端调用一个事件``broadcast(blob)`` ,那么每个正确的peer节点“最终”发出一个事件``deliver(*, *, blob)``,其中
*表示一个任意值。
2. 交易背书的基本流程¶
在下面的文章中,我们将概述交易的高级请求流程。
注: 注意以下协议*并不*假设所有交易都是确定性的,即,它允许非确定性交易。
2.1. 客户端创建一个交易并将其发送给它所选择的背书peer节点¶
要引起一个交易,客户端向其选择的一组背书peer节点发送一条“建议”消息(可能不是同时发送,参见2.1.2.节和2.3.节)。客户端可以通过peer节点获得给定“chaincodeID”的背书peer节点集,而peer节点又从背书策略中知道背书peer节点集合(参见第3节)。例如,可以将交易发送给给定``chaincodeID``’的*所有*背书节点。。也就是说,一些背书节点可能离线,其它背书节点可能会反对并选择不背书交易。提交客户端尝试使用可用的背书者来满足策略表达式。
在下面,我们首先详细介绍“提议”消息格式,然后讨论提交客户端和背书者之间可能的交互模式。
2.1.1. ``提议``消息格式¶
:’ ‘ proposal ‘ ‘消息的格式是’ ‘ < proposal,tx,[anchor]> ‘ ‘,其中’ ‘ tx ‘ ‘是必填参数,’ ‘ anchor ‘ ‘可选参数解释如下。
提议``消息的格式是 ``<PROPOSE,tx,[anchor]>,其中``tx`` 是必填参数,可选参数 anchor 解释如下。
tx=<clientID,chaincodeID,txPayload,timestamp,clientSig>, 其中clientID是提交客户端的ID,“chaincodeID”指向交易所属的链码,
``txPayload``是包含提交交易本身的载荷,
“timestamp”是客户端维护的一个简单递增的整数(对于每个新交易),
“clientSig”是客户端在“tx”的其他字段上的签名。
“txPayload”的详细信息在调用交易和部署交易(即调用交易引用特定于部署的系统链码)是不同的。对于**调用交易**, ``txPayload``将包含两个字段
txPayload = <operation, metadata>, 其中``operation``表示链码操作(函数)和参数,
“metadata”表示与调用相关的属性。
对于一个**部署交易**,
txPayload将包含三个字段txPayload = <source, metadata, policies>, 其中source表示链码的源代码,metadata表示与链码和应用程序相关的属性,``policies``包含与链码相关的策略,所有peer节点都可以访问这些策略,例如背书策略。注意,在“部署”事务中的“txPayload”中没有提供背书策略,但是“部署”的“txPayload”包含背书策略ID及其参数(参见第3节)。
``锚定``包含*读取版本依赖项*,或者更具体地说,键版本对儿(即``anchor``是 ``KxN``的子集),它将 ``提议``请求绑定或 “锚定”到KVS中指定版本的键(请参阅1.2.)。如果客户端指定了``锚定``参数,背书者仅在其本地KVS中对应键的*读*版本号匹配``锚定``时才背书交易(更多的细节参见第2.2节)。
所有node节点都使用``tx``的加密哈希作为惟一的交易标识符``tid`` (即``tid=HASH(tx)``)。客户端在内存中存储``tid``,并等待来自背书节点的响应。
2.1.2. 消息模式¶
客户端决定与背书者交互的顺序。例如,客户端通常会发送``<PROPOSE, tx>`` (即没有“锚定”参数)到单个背书者,这将生成版本依赖关系(“锚定”),客户端稍后可以将该依赖关系用作其向其他背书者发送的“提议”消息的参数。另一个例子是,客户端可以直接将``<PROPOSE, tx>``(没有’锚定)发送给它所选择的所有背书者。不同的通信模式是可能的,客户端可以自由决定这些模式(参见2.3.)。
2.2. 背书节点模拟交易并生成背书签名¶
当接收到来自客户端的``<PROPOSE,tx,[anchor]>`` 消息时,背书节点 epID 首先验证客户端的签名``clientSig``,然后模拟一个交易。如果客户端指定“锚定”,则背书节点在它的本地KVS中仅根据键对应的读版本号匹配由 ``锚定``指定的版本号。
通过调用交易引用的链码(“chaincodeID”)和背书节点本地持有的状态副本,模拟交易包括暂时*执行*一个交易(“txPayload”)。
执行的结果是,背书节点计算*读版本依赖项* (readset)和*状态更新* (writeset),在DB语言中也称为*MVCC+postimage info*。
回想一下,状态由键值对组成。所有键值条目都有版本控制;也就是说,每个条目都包含有序的版本信息,每次更新存储在键下的值时,该信息都会增加。解释交易的peer节点记录链码访问的所有键值对(无论对于读取或写入),但该peer节点尚未更新其状态。更具体地说:
背书peer节点在执行一个交易之前的给定的状态``s`` ,交易读取的每个键``k`` ,键值对
(k,s(k).version)``被添加到``readset。此外,对于被交易修改为新值到
v'``的每个键``k,键值对``(k,v’)``被添加到``writeset``中。或者,v'``可以是新值与旧值的差值 (``s(k).value)。
如果客户端在“提议”消息中指定“锚定”,则客户端指定的“锚定”必须等于模拟交易时由背书peer生成的“readset”。
然后,peer节点将内部的“tran-proposal”(可能还有“tx”)转发给它的(peer节点的)背书交易的逻辑部分,称为**背书逻辑**。默认情况下,在peer节点中背书逻辑接受“tran-proposal”,并简单地签署“tran-proposal”。然而,背书逻辑可能会解释任意的功能,例如,使用“trans -proposal”和“tx”做输入与遗留系统交互,来决定是否为交易背书。
如果背书逻辑决定背书一个交易,它会向提交客户端(tx.clientID)发送``<TRANSACTION-ENDORSED, tid, tran-proposal,epSig>``消息,其中:
tran-proposal := (epID,tid,chaincodeID,txContentBlob,readset,writeset),其中``txContentBlob``’是链码/交易指定信息。其目的是将``txContentBlob``用作
tx的某种表示形式(例如``txContentBlob=tx.txPayload``)。“epSig”是背书节点在“tran-proposal”上的签名。
否则,如果背书逻辑拒绝对交易进行背书,背书者*可以*向提交的客户端发送一条消息``(TRANSACTION-INVALID, tid, REJECTED)`` 。
请注意,背书者在此步骤中不会更改其状态,背书上下文中交易模拟生成的更新不会影响状态!
2.3. 提交客户端为交易收集背书并通过排序服务广播¶
提交客户端等待,直到它收到“足够”的消息和``(TRANSACTION-ENDORSED, tid, *, *)`` 语句上的签名,从而断定交易提议已被背书。如第2.1.2节所述,这可能涉及与背书者的一次或多次双向互动。
确切数目是否“足够”由链码背书策略而定(另见第3条)。如背书策略符合,则交易已获*背书*;注意,它还没有提交。来自背书节点的已签章“ ``TRANSACTION-ENDORSED``消息称为*背书*,并用“背书”表示。
如果提交的客户端未能为交易提议收集到背书,它将放弃该交易,并提供稍后重试的选项。
对于具有有效背书的交易,我们现在开始使用排序服务。提交客户端使用“broadcast(blob)”调用排序服务,其中“blob=背书”。如果客户端没有直接调用排序服务,它可以通过自己选择的某个peer节点代理其广播。客户端必须信任这样的peer节点不会从“背书”中删除任何消息,否则交易可能被视为无效。但是,请注意,代理peer节点不可以伪造有效的“背书”。
2.4. 排序服务向peer节点交付交易¶
当一个事件 deliver(seqno, prevhash, blob) 发生,并且一个peer节点为序号小于 ``seqno``的blob应用了所有状态更新时,peer节点执行以下操作:
它根据所引用的链码(
blob.tran-proposal.chaincodeID)的策略检查``blob.endorsement``’是有效的。在典型的情况下,它还验证依赖项(
blob.endorsement.tran-proposal.readset)没有同时被违反。在更复杂的用例中,背书中的“trans -proposal”字段可能有所不同,在这种情况下,背书策略(第3节)指定状态如何发展。
根据为状态更新选择的一致性属性或“隔离保证”,可以以不同的方式实现依赖项的验证。**Serializability**是默认的隔离保证,除非链码背书策略指定了一个不同的隔离保证。通过要求``readset``中的*每个*键关联的版本等于该键在状态中的版本,提供了Serializability,并拒绝不满足此要求的交易。
如果所有这些检查通过,交易将被视为“有效”或“已提交”。在本例中,peer节点在“PeerLedger”的比特掩码中使用1标记交易,应用``blob.endorsement.tran-proposal.writeset``到区块链状态(如果 ``tran-proposals``相同,否则背书策略逻辑定义接受 ``blob.endorsement``的函数)。
如果背书策略验证``blob.endorsement``失败,交易无效,在``PeerLedger``的比特掩码中,peer节点将交易标记为0。需要注意的是,无效交易不会更改状态。
注意,在使用给定的序列号处理一个交付事件(区块)之后,所有(正确的)peer节点都具有相同的状态就足够了。也就是说,通过排序服务的保证,所有正确的peer节点将接收相同的``deliver(seqno, prevhash, blob)``事件序列。由于对背书策略的评估和对“readset”中的版本依赖关系的评估是确定的,所以所有正确的peer节点也会得出相同的结论,即blob中包含的交易是否有效。因此,所有peer节点提交和应用相同的交易序列,并以相同的方式更新它们的状态。
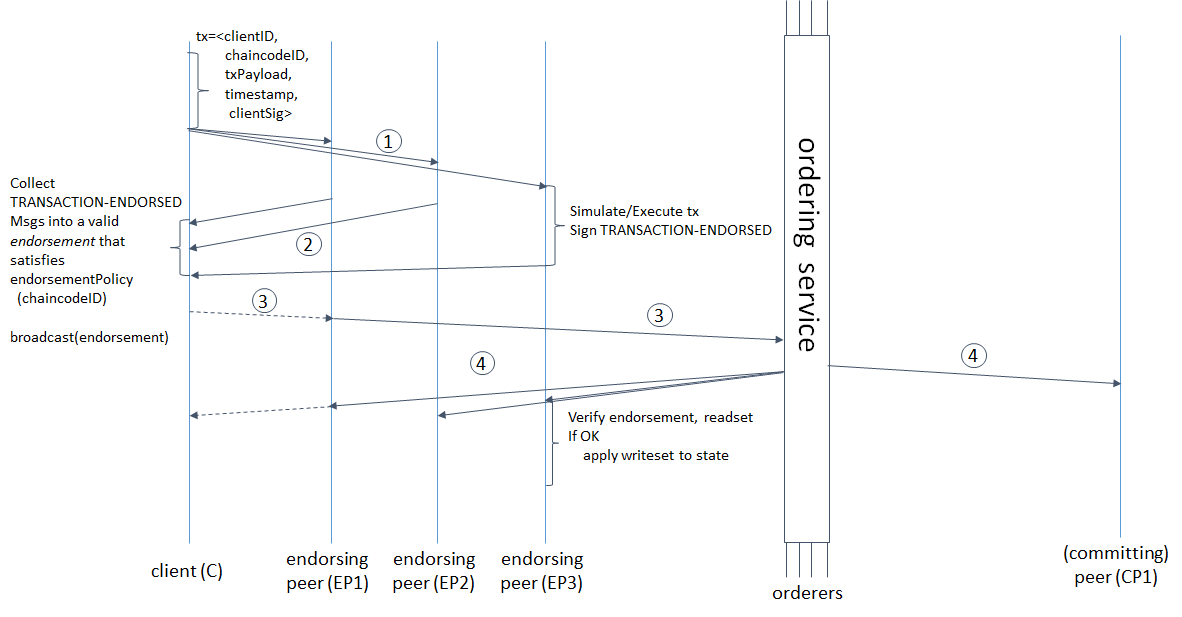
图1 . 说明一种可能的交易流程(常见情况路径)。
3. 背书策略¶
3.1. 背书策略规范¶
**背书策略**是*背书*交易的条件。区块链peer节点有一组预先指定的背书策略,这些策略由安装特定链码的 ``部署``交易引用。背书策略可以参数化,这些参数可以通过“部署”交易指定。
为了保证区块链和安全性属性,背书策略集**应该是一组经过验证的策略**,具有有限的函数集,以确保有限的执行时间(终止)、确定性、性能和安全性保证。
在有限的策略评估时间(终止)、确定性、性能和安全性保证方面,背书策略的动态添加(例如通过链码部署时的“部署”交易)非常敏感。因此,背书策略的动态添加是不允许的,但可以在将来支持。
3.2. 根据背书策略进行交易评估¶
只有根据策略进行了背书,交易才被声明为有效。链码的调用交易首先必须获得一个满足链码策略的*背书*,否则不会提交。这是通过提交客户端和背书节点之间的交互来实现的,如第2节所述。
形式上,背书策略是对背书的断言,并且可能是其计算结果为TRUE或FALSE的进一步的状态。对于部署交易,背书是根据系统范围的策略(例如从系统链码)获得的。
背书策略断言引用某些变量。可能是指:
与链码相关的键或标识(可在链码元数据中找到),例如,一组背书器;
链码的进一步元数据;
“endorsement”和``endorsement.tran-proposal``的元素;
并且可能更多。
上面的列表是通过渐增的表达性和复杂性来排序的,也就是说,支持只引用node节点的键和身份的策略将相对简单。
背书策略断言的计算必须是确定的。**背书应由每一个peer节点在本地进行评估,以便该peer节点不需要与其他节点进行交互,但所有正直的peer节点对背书策略的评估是相同的。
3.3. 背书策略的例子¶
断言可以包含逻辑表达式,并且计算为TRUE或FALSE。通常情况下,该条件将在交易调用上使用数字签名,签名由为链码背书的peer节点签发。
假设链码指定背书集合 E = {Alice, Bob, Charlie, Dave, Eve, Frank, George}。一些示例策略:
E所有成员在相同``tran-proposal`` 上的一个有效签名。
E的任何一个成员的有效签名。
根据条件``(Alice OR Bob) AND (any two of: Charlie, Dave, Eve, Frank, George)``,在相同``tran-proposal``上来自背书节点的有效签名。
七名背书者中的五名在同一份``tran-proposal`` 上的有效签名。(更一般地说,对于具有``n > 3f``个背书者的链码,由``n``背书者中的任意``2f+1``个进行有效签名,或由多于``(n+f)/2``个背书者组成的任何组合进行有效签名。)
假设有一个“股份”或“权重”分配给背书者,如
{Alice=49, Bob=15, Charlie=15, Dave=10, Eve=7, Frank=3, George=1},其中总股份为100:该策略要求的有效签名来自大多数股份的集合(例如组合股份严格大于50的组合),例如,{Alice, X},X不能是George,或{出了Alice的全体组合在一起}。等等。在前面的示例条件中,股份的分配可以是静态的(在链码的元数据中固定),也可以是动态的(例如,取决于链码的状态,并在执行过程中进行修改)。
(Alice或Bob)在“tran-proposal1”上的有效签名,以及在“tran-proposal2”上的有效签名(查理、戴夫、伊芙、弗兰克、乔治中的任意两人),其中“tran-proposal1”和“tran-proposal2”的有效签名仅在背书节点和状态更新上存在差异。
这些策略的有用程度将取决于应用程序、解决方案对背书者的失败或不当行为的预期弹性,以及各种其他属性。
4 (post-v1). 验证账本和“PeerLedger”检查点(修剪)¶
4.1. 已验证账本 (VLedger)¶
为了维护只包含有效和已提交交易(例如比特币的作法)的账本抽象,peer节点可以在状态和账本之外维护*已验证(或VLedger)*。这是从账本中过滤掉无效交易而得到的哈希链。
VLedger区块(这里称为*vBlocks*)的构建过程如下。因为“PeerLedger”区块可能包含无效的交易(例如具有无效背书或无效版本依赖项的交易),在将来自区块的交易添加到vBlock之前,peer节点将筛选掉此类交易。每个peer节点都自己做这件事(例如,使用与``PeerLedger``关联的比特掩码)。vBlock被定义为一个不含无效交易的区块,无效交易被过滤掉了。这样的vblock在大小上是动态的,可能是空的。下图给出了vBlock构造的一个例子。
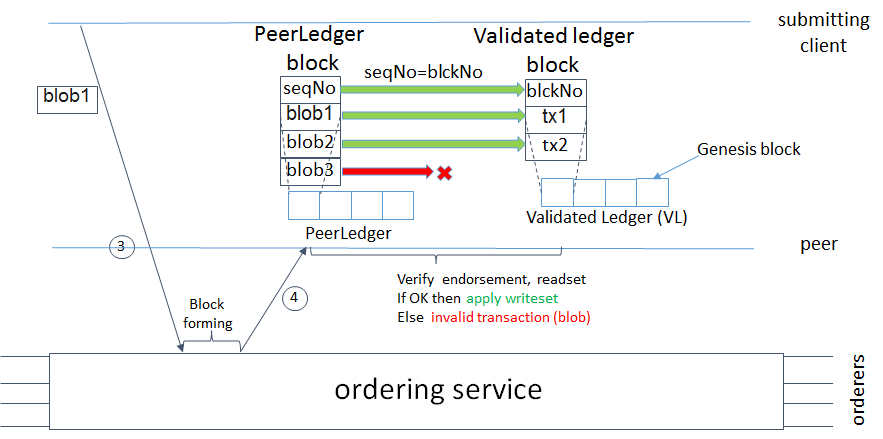
图2. 从账本(PeerLedger)区块中生成已验证区块(vBlock)的图解。
每个peer节点都将vBlocks链接到一个哈希链上。更具体地说,每一个已验证账本包含:
前一个vBlock的哈希值。
vBlock号码。
自最后一个vBlock被计算以来,peer节点提交的所有有效交易的有序列表(即相应区块中的有效交易列表)。
对应区块的哈希值(在``PeerLedger``中),当前vBlock就是从中派生出来的。
所有这些信息都由一个peer节点连接和哈希,在已验证账本中生成vBlock的哈希。
4.2. PeerLedger 检查点¶
账本包含无效的交易,不一定要永远记录。然而,peer节点不能简单地丢弃``PeerLedger``区块,从而在他们建立了相应的vBlocks之后修剪``PeerLedger``。也就是说,在这种情况下,如果一个新的peer节点加入网络,其他peer节点不能将丢弃的区块(属于“PeerLedger”)转移到加入的peer节点,也不能说服加入的peer节点他们的vBlock的有效性。
为了方便修剪``PeerLedger``,本文档描述了一个*检查点*机制。该机制建立了跨peer网络的vBlock的有效性,并允许检查点vBlock替换被丢弃的``PeerLedger``区块。这进而减少了存储空间,因为不需要存储无效的交易。它还减少了为加入网络的新peer节点重构状态的工作(因为当通过重放``PeerLedger``来重构状态时,它们不需要建立单个交易的有效性,而只需重放已验证账本中包含的状态更新)。
4.2.1. 检查点协议¶
每个*CHK*区块的peer节点定期执行检查点,其中*CHK*是一个可配置参数。为了发起一个检查点,peer节点广播(例如gossip)消息``<CHECKPOINT,blocknohash,blockno,stateHash,peerSig>``到其它peer节点, 其中``blockno`` 是当前区块号和“blocknohash“是其各自的哈希,“stateHash“是根据区块的``blockno``验证的最新状态的哈希(例如,产生自Merkle哈希),``peerSig``peer节点在``(CHECKPOINT,blocknohash,blockno,stateHash)``的签名,指的是已验证账本。
一个peer节点收集``CHECKPOINT``消息,直到它获得与``blockno``、blocknohash 和``stateHash`` 匹配的足够正确签名的消息,以建立一个*有效的检查点*(参见4.2.2.)。
在为区块号``blockno`` 和``blocknohash``建立一个有效的检查点时,一个peer节点:
如果
blockno>latestValidCheckpoint.blockno,则peer赋值latestValidCheckpoint=(blocknohash,blockno),将构成有效检查点的各peer节点签名集合存储到集合``latestValidCheckpointProof``中,
存储与
stateHash``对应的状态到``latestValidCheckpointedState,(可选)修剪它的“PeerLedger”“到区块号“blockno”(包括)。
4.2.2. 有效的检查点¶
显然,检查点协议提出了以下问题:peer节点何时可以删除其“PeerLedger”?有多少“检查点”消息是“足够多的”?。这是由一个*检查点有效性策略*定义的,有(至少)两种可能的方法,也可以组合使用:
*本地(特定于peer节点)检查点有效性策略(LCVP)。*一个给定peer节点*p*的本地策略可以指定节点*p*信任的一组peer节点,并且它们的“CHECKPOINT”消息足以建立有效的检查点。例如,节点*Alice*的LCVP可能定义*Alice*需要从Bob、或同时从*Charlie*和*Dave*接收“CHECKPOINT”消息。
*全局检查点有效性策略(GCVP)。可以全局指定检查点有效性策略。这类似于本地peer节点策略,只是它是在系统粒度(区块链)而不是peer节点粒度中规定的。例如,GCVP可以指定:
如果得到*11*个不同的peer节点确认,每个peer节点都可以信任这个检查点。
在特定的部署中,每个排序器都在同一台机器中(即信任域)搭配了一个peer节点,即当多达*f* 个排序器可能(拜占庭式的)错误时,如果由*f+1*与排序器一起配置的不同peer节点确认,每个peer节点都可以信任检查点。